D.3.9
Discuss the features of modern programming languages that enable internationalization.
Teaching Note:
For example, use of UNICODE character sets.
INT When organizations interact, particularly on an international basis, there may be issues of language differences.
Sample Question:
----
In relation to the Doctor object, outline the need for extended character sets as used
by modern programming languages.
----
Discuss the features of modern programming languages that enable the program to be
sold in other countries
----
sdfsdfsf
JSR Notes:
Related Links
For an introductory understanding of ASCII and UNICODE, do take a look at this "How Computers Work - Day 1".
And for a more complete understanding of UNICODE, a big part of 2.1.10 is an in-depth discussion of UNICODE.
Internationalization vs. Localization
There are two parts/steps for enabling a program to be ready to be used in many different countries/regions.
Step 1 - Internationalization
This is done once, and includes adding all of the features that "set up" a program for potential use/customization in a particular market.
Step 2 - Localization
This
is a specific customizing process of readying a program for a particular market, or "locale".
Internationalization
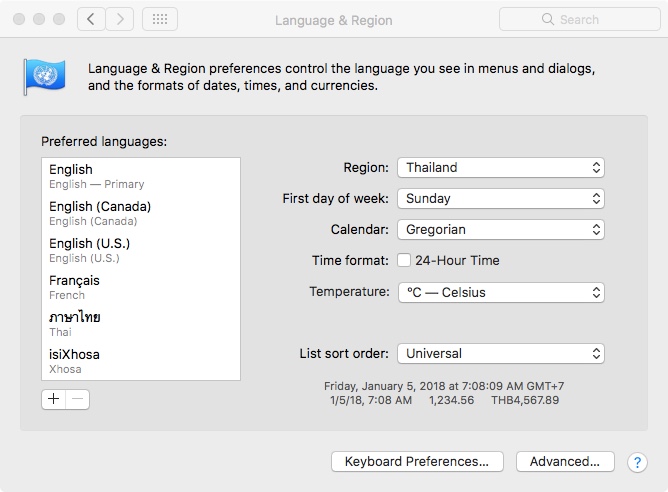
Software application that are intended for an international market need to be designed and engineered so that they can potentially be adapted to various languages and regions without further engineering (i.e. programming) changes. And even if you are not sure where the program will be used, you should do your best to include flexibility in several areas, such as:
- language
- spelling
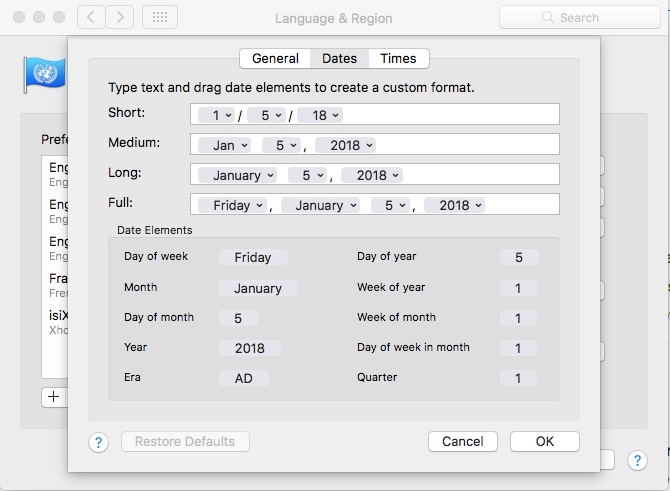
- calendar
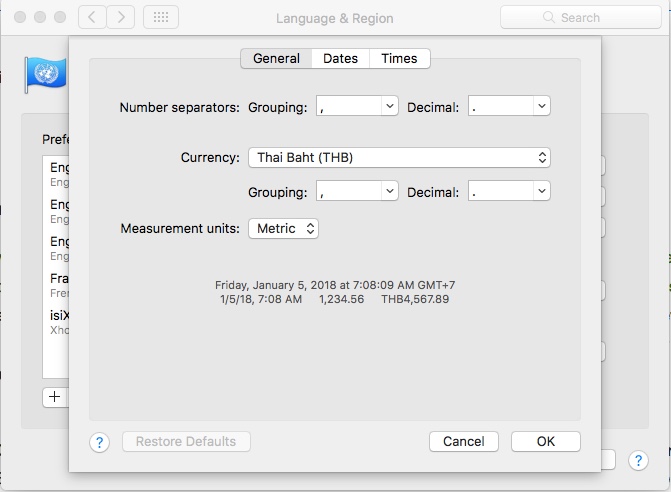
- number
- currency formatting
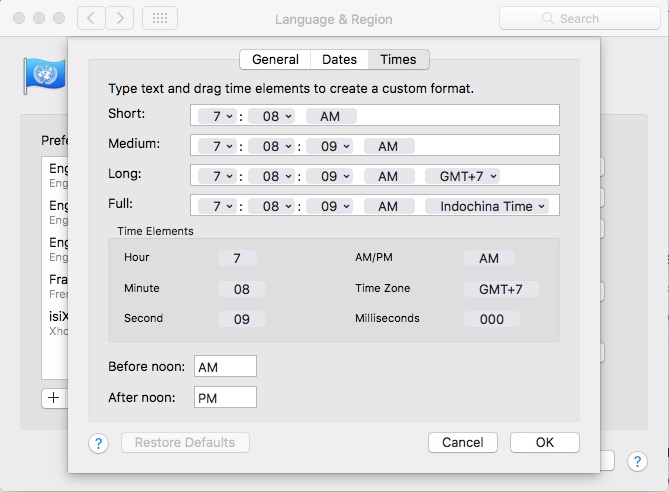
A good place to get a flavor (or is that flavour? :-) of this is the Language and Region System Preference of the Mac OS, a software program most certainly well internationalized:
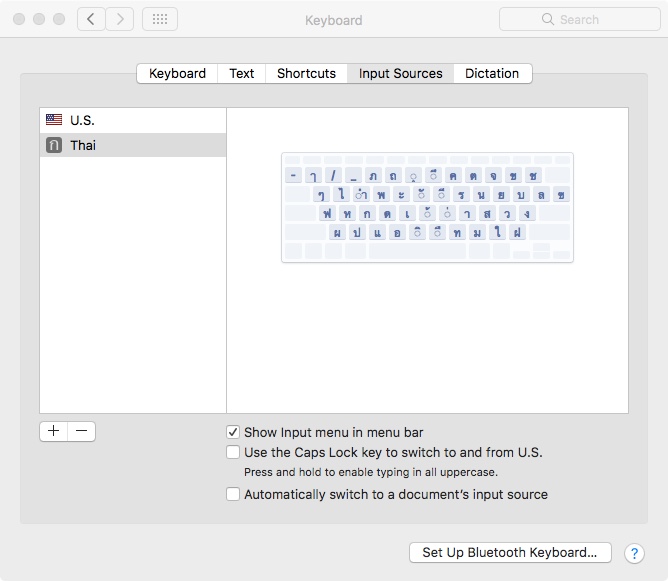
Localization
Localization is the process of adapting internationalized software to a specific country or region by enabling locale-specific components, and double-checking to make sure all required locale-specific features are present, and properly functioning.
Localization will be potentially performed multiple times, for different locales, using the programmed flexibility provided by internationalization. In the process of localization, core programming should not have to be re-engineered; ideally, that core internationalization is programmed only once.
So to reiterate, internationalization is done once, implementing flexibility from the start. And localization is done as/when needed for a specific localized context - for example enabling Thai script, and the Thai calendar to an application for use in Thailand.
Who does Localization?
Note that in the Mac OS example above, it is the user themselves who can do the localization. But most of the time, for specific software applications, the localization will be done by the software company itself on a country-by-country basis, or alternatively by the distributor, or even a technician at a retail outlet.
Key Features enabling Internationalization and Localization
When making programming decisions, two things can help add to the flexibility of your internationalization.
- Platform independent high level languages (like Java) enable code to run on many platforms.
- Use of common character sets, which support many languages and scripts, like UNICODE.
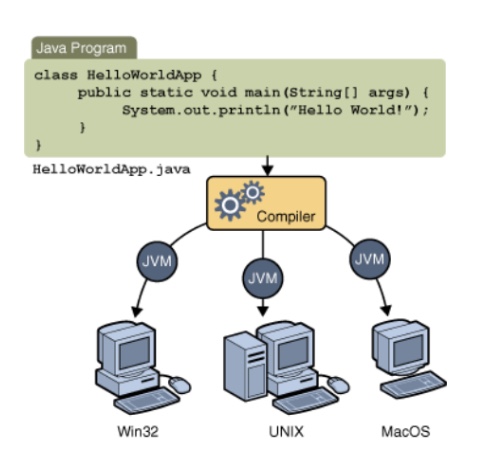
Java Cross-platform Independence
The way Java works as a programming language, it can run on any computer that has an operating system which has a "Java Virtual Machine", and all mainstream operating systems do support this ability. So you don't have to worry that users in a particular region can't use your program because of a particular operating system used there. And neither do you need to produce several different versions of your program, one for each operating system. All you need to do is produce one.
The technical details are covered elsewhere in the curriculum, but basically, when a Java program is compiled, it is only actually "half-compiled" to a .class file, which then goes on to being compiled the rest of the way, or translated, by the particular Java Virtual Machine installed on a particular kind of computer.
Frankly, this is as much an "intra"-national advantage as it is an international advantage, but the point is that the more flexible you can make all aspects of your program, the more easily and widely distributed it can be.
UNICODE
Unicode is a computing industry standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems, maintained by the Unicode Consortium. On June 20th, 2017, they released the latest version, UNICODE 10.0.0.
![]()
https://unicode-table.com/en/#control-character
When it was first devised, UNICODE used 16 bits per character, and so supported, 2 ^ 16, or 65,536 characters. But even though it presently still uses a 16 bit code set, Unicode allows for 17 planes, each of 65,536 possible characters (or 'code points'). This gives a total of over a million possible characters. At present, about 128,000 of this space has been allocated for around 135 modern and historic scripts, along with multiple symbol sets.
Java developed the char data type in a strictly 16-bit way. So at the point when UNICODE was expanded, Java could not change its 16 bit char. But there is a workaround for the now possible "supplementary characters", which is to use a pair of chars. And so Java is still able to work with characters from most scripts in the world.
In Summary, Back to the Assessment Statement:
"Discuss the features of modern programming languages that enable internationalization."
The features that enable the program to be used in many countries include the use of international character sets, such as UNICODE (so not being limited by ASCII), having other localization features available due to proper internationalization at the time of initial engineering, and being programmed in "portable" programming languages such as Java.