Types, Structures & ADTs
(Notes below)
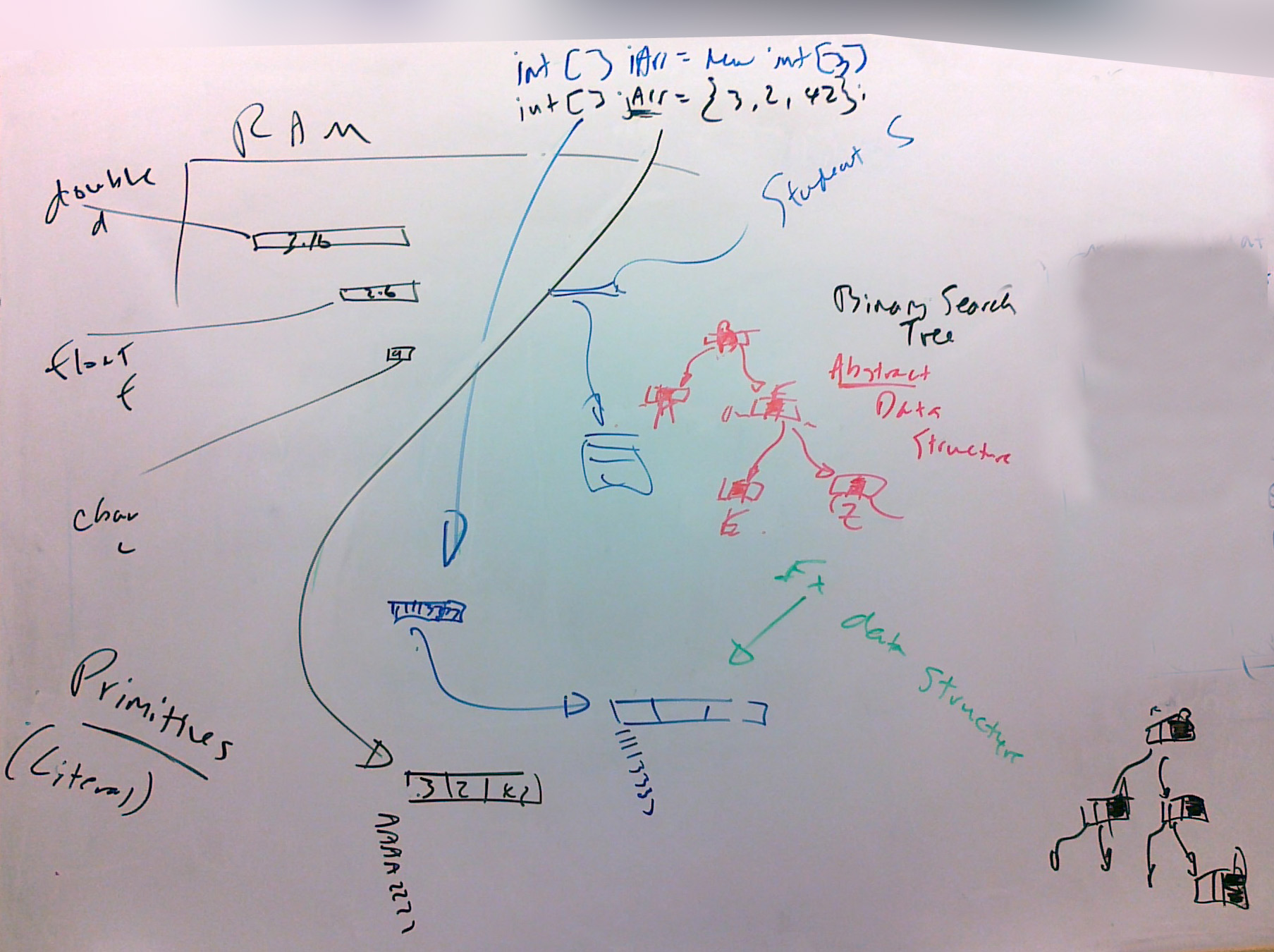
(Images such as this are not meant to be either the last word, or works of art; rather they are intended to help make connections back to class.)
Types
All programs can be said to be made up of two general things: data and method that work on that data. The data is of specific types, which are defined, fundamentally, by the amount of memory they take up. A type can be either a primitive type or a reference type.
From primitive types we can make variables which are literally the value they are to store. So if I have int i = 3, then i is a short-cut for the value 3, literally. So we call variables of primitive types literal variables.
With reference types, we make variables which are actually references to the data to be worked with. So if we have Student s = new Student("John", 11, true), then s a shortcut for a reference to where the three attributes are stored. The reference and its data can be referred to collectively as an object, though technically the object is the reference (i.e. the address of where the data of the object starts being stored).
Structures
When a bunch of a certain type, or types is grouped together, we say that what is grouping them is a data structure. Some data structures are defined by the programming language - the array is the prime example of this in Java. Other structures are created by the programmer, with the used of other predefined types and/or structures. These structures are referred to as "abstract" because there is no set, agreed upon, concrete way of creating them (though there are generally agreed upon approaches for each). So "structures" used in Java are either Java structures, or Abstract Data Structures.
Abstract Data Structures (ADTs)
So ADTs are created by the programmer, based on some generally agreed upon approach to structuring data. The five we look at in IB CS are the linked list, the linked list operating in a stack fashion, the linked list operating in a queue fashion, the binary search tree, and the hash table.
In brief:
A linked list is a bunch of data "nodes" which are linked together by "pointers" which point to the address of the next node in the link.
A stack is a linked list, in which the data is accessed in the following way: the last item in is the first item that can be accessed. This is called LIFO - "Last In First Out" - access.
A queue is a linked list, in which the data is accessed with the first item in being the first out. This is called FIFO - "First In First Out" - access.
A binary search tree is similar to a linked list, except that each node has two links; one to something "greater" than it, and one "lesser" than it. Binary search trees are often referred to simply as search trees.
A hash table is an array in which the items are placed according to a calculation, which can be repeated to find the element in question. This allows direct (or fairly direct, in the case of ties) access, rather than having to rely on sequential or binary searches.