Random Access Adding and Searching By Hashing
In fact, "non-hashable" "random access file" is oxymoronic. The idea of a Random Access File (RAF) is that you can directly access a part of the file to save a record there, and repeat the process to directly access records stored in the file. With the sequential examples presented earlier, you are simply doing a sequential search for either the next free spot in the file, or the record you are looking for; there is nothing direct about that. So, particularly if you are looking to get all three RandomAccessFile Mastery Aspects, you should use the hashing approach.
Terms:
These terms apply to all files one way or the other, but just to classify:
File - a named collection of records saved to a secondary storage device.
Record - one individual part of a file; the basis upon which a file is divided up. A record is made up of one or more fields.
Fields - what make up records. Fields can usually be thought of of having a certain data type, for example, a String field for holding a student's name, a boolean field for holding whether or not they are female, and an in for holding their grade.
Key Field - A field which is unique; the field which will thus be the one used for hashing.
Though the code is not that long for either the adding or the hashing method, it is a bit on the sophisticated and tricky side.
Basic Idea:
The basic idea is that you are combining the workings of a RandomAccessFile with that placement and searching algorithms of a hash table. So you hash a key field of a record and then use that number to make a calculation to find an appropriate place to put that record. And as with hash tables, if there is already something being stored there, you have a tie breaking algorithm, most often just a linear search from that point to the nearest avaiable spot. The same hashing and tie breaking algorithms are used to find records and access them in a direct manner.
Parts That Make It A Tricky Algorithm
- You can't just place the record at an element number - as with a hash table, rather you have to do a calculation to determine the exact number of bytes into the file where the record should be placed. So it's the hash value times the record length.
- The "pointer" is not something very tangible; rather it is just wherever the readUTF() method will read next. So the seek() method is certainly one way to "move" the pointer, but so is using the readUTF() method, since it reads a UTF and "stays" there at the end of where it just read.
- The add method and the search method will work slightly differently with how they use the hash value, and how the seek() and readUTF() methods move the pointer around.
Fully Annotated Code
(click herer for a cleaner version, not so annotated)
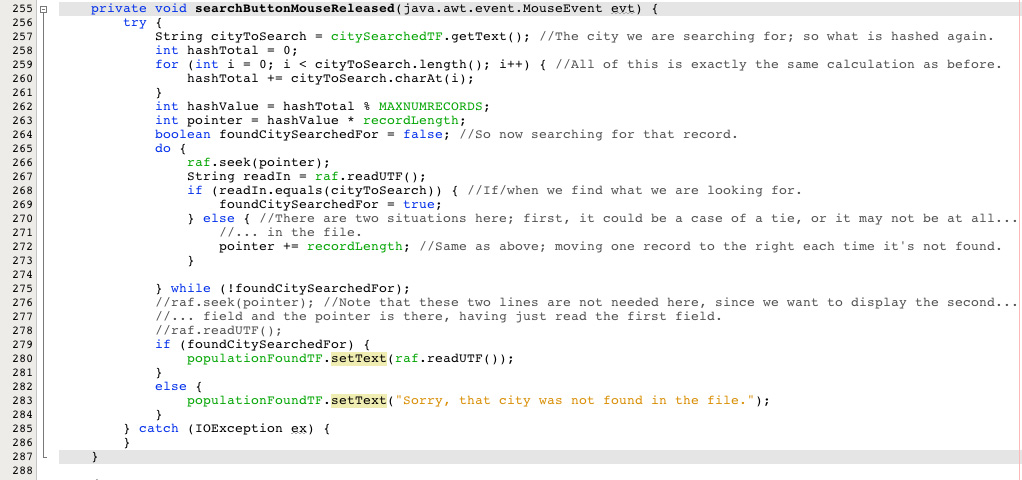
Our init() Method:
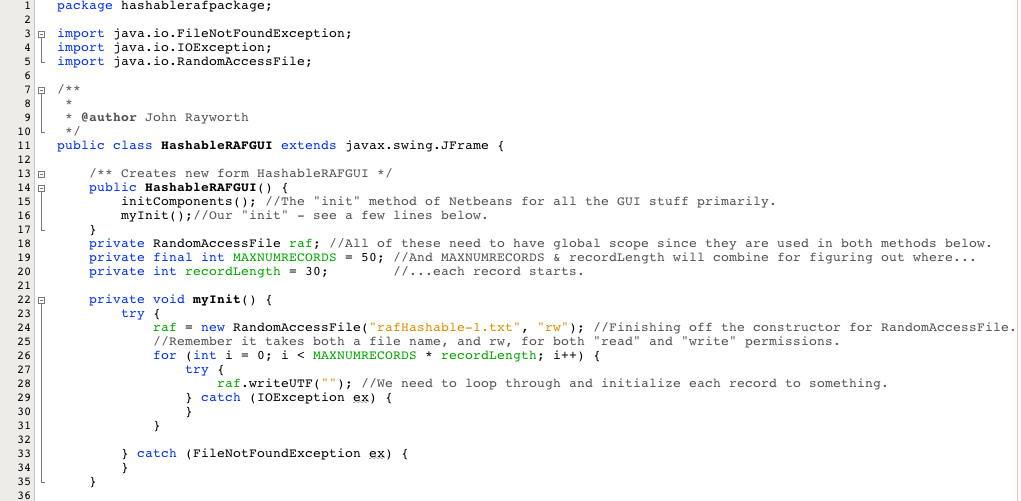
The add() Method:
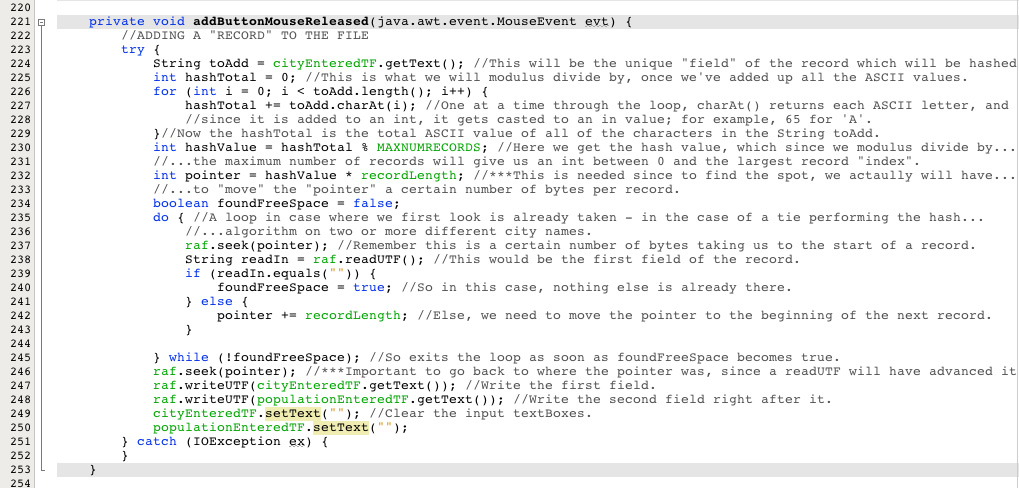
The search() Method: