Here's the rest of the story regarding the mysterious calculation referred to in the explanation of finding records in a direct access file. You performa what is called a "hash calculation", which results in a "hash result", which will be the order number of the record in the file. So if the hash result is 5, then that record gets put in the 5th spot in the file.
One easy and common hash calculation is to take the key field (the field which has a unique name and/or number), add up the ASCII values of its letters and/or numbers, and perform modulus division by the prime number closest to the total number of records. This will yield results which are from close to 0 or 0, up to approximately the number of records. These results then become the address of the record in the file, kind of like the element number of an array. The use of a prime number modulus divisor helps with preventing ties, but there will still be ties ("abc" and "cba", for example, will yield the same result), so there are various tie-breaking strategies. The easiest thing to do if a particular hash value has already been generated (and so that space already taken up), is just look sequentially from there on for the first available free space.
Then, for finding the record, you do exactly the same calculation on exactly the same field. And you check to see if what you are looking for is held in that position. If it is not, that means there had been a tie in the initial hashing process, so as with the creation of the file, you sequentially search from that point on, and you'll quickly find what you are looking for.
----------------------------
When you think of the bother of sequentially accessing a record, versus the speed and accuracy of the direct access of a hard drive, for example, you may have a hard time wondering why we don't always use direct access. But there are indeed pluses and minuses of each structure, and times and places when one or the other is most appropriate to use. As ever it boils down to two efficiencies: speed, and memory consumption.
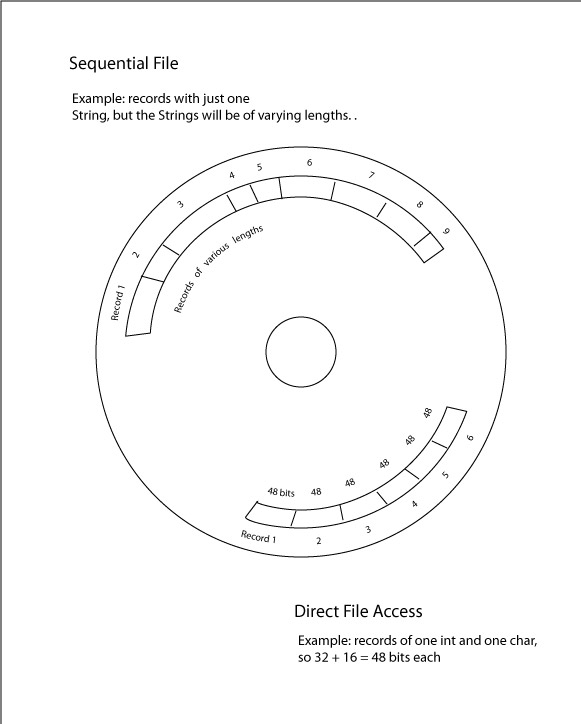
The major advantage of direct access file structure is the speed at which an individual record in the file can be found. The only limit is the time it takes to do the calculation, which is negligible, and then the time it takes the hard drive read head to rotate to the file, which is also almost instantaneous. But the disadvantage is that in order to find the record, all records in the file must be the same size. For the way the record is found is by multiplying the result of the calculation by the set size of an individual record. So let's say the file is a bunch of records that are two ints and a char each. That makes each record 32 bits + 32 bits + 16 bits, or 80 bits per record. And if we do the calculation on the record we're looking for and we get 20, we multiply 20 x 80, and know that the record we are looking for is 1600 bits in from the beginning of the file. This only works since each record is exactly 80 bits.
Here's the problem with this approach. What if the size of one of the fields is indefinite; primarily, what if one of the fields is a String? Not all Strings are the same size, since they are an array of chars and are naturally varying numbers of chars. The only solution is to pick a hypothetically maximum size of the String, and make all records' String fields that size. In the example of airport-to-airport records, if one of the fields was the city name and country, then we'd have to accommodate long names like Kinshasa, The Democratic Republic of Congo, so we'd pick a size of say 50. So when saving a city/country combo like Xi, China, we would be wasting a lot of space which would just sit empty in the file. We could live with this, since we're only talking dozens of wasted bits, but what if one of the fields was a media file, such as in our music database example. A very long song, such as Stairway To Heaven would require, say 9 million bits to store, so if we made that our size for the media field of our record, then short songs like Teenage Lobotomy would take up only a fraction of that space, wasting millions of bits of storage per record. This is an extreme example, but clearly illustrates the point.
The main advantage of sequential files is that they do not require fixed record lengths, since no calculation is made to locate the record being searched for. Rather, the whole file is written all together from the first bit of the first field of the first record of the file, right to the last bit. So sequential files are much more memory efficient, particularly in cases where certain fields will by nature have varying lengths from record to record.
But the disadvantage to a sequential file is obvious: it's simply slow at finding records, since a search from the very beginning of the file needs to be made. For files of smaller numbers of records, this won't be such a big deal, but the bigger the number of records; indeed the bigger the size of the fields of each record, the slower the average search will take. Naturally some searches will be quick, since the key value will be near the front, but other times it will be near the end, so the average search time will be the time it takes to find a record in the middle.
Sequential files are therefore best used for when all of the file will be loaded from storage to RAM memory all at once, as is often the case when you start to use a program. Then, when you quit the program, you can "dump" the data back into the file very easily.
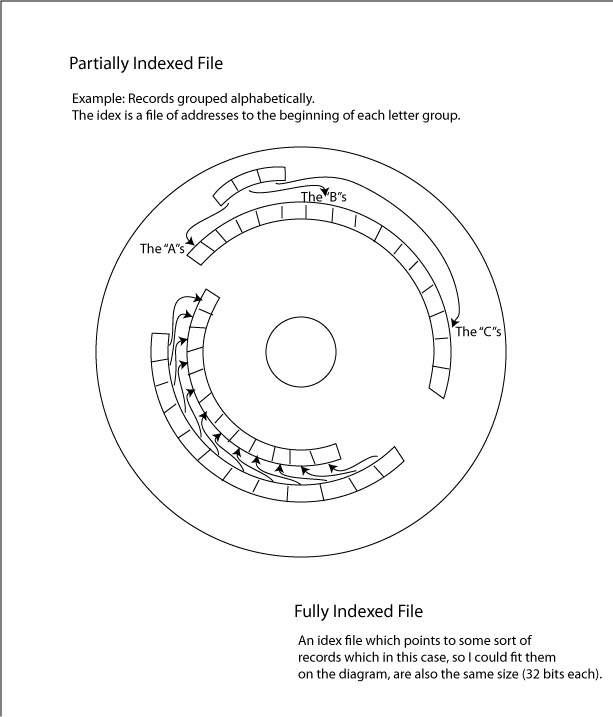
In some respects indexed files take the best of sequential and the best of direct access structures.
With the partially indexed file, yes, it requires a slow sequential search through the index file, and then another short sequential search through the group it is directed to, but these will be much quicker than a full sequential search through the whole file. The sequential search of the index file will be particularly quick given the size of it, since each record is only one field, a 32 bit address.
With the fully indexed file, the sequential search through the index file will be generally longer since each record has its own corresponding address in the index file. But again, the records in the index file are only 32 bits each, whereas who knows how big each record is in the data file itself. And with the fully indexed file, there is no second sequential search through the data part of the file, since the address of the actual record is found in the sequential search through the index, not just the group of records in which it is (like with the partially indexed file.)
So for both fully and partially indexed files, there are speed efficiencies relative to the sequential search.
And for both fully and partially indexed files, there are memory efficiencies relative to the direct access file. This is because records can be varying lengths; the index "finds" either the group of records, or the specific record with a memory address stored in the index file, not through a hash calculationi.
For average small to medium sized records, a partially indexed file structure will be quickest. Consider a file of 1,000,000 records grouped in 1000 groups of 1000 records. The worst case scenario (WCS) would be sequentially searching to the last of the index file, and then sequentially searching through to the end of the group pointed to. That would be 1000 + 1000 steps, or 2000 steps in total. Compare that to the 1,000,001 steps which would be the worst case scenario of searching entirely through a fully indexed file of 1,000,000 records, and then the extra one direct step to the record.
But (and this is the part that I didn't get to in class), if the records are really big, the partially indexed search could actually be slower. That is because the 1000 search steps of the data group could take a very long time if the records themselves are each quite big. Compare this to only having to look at the small (only 32 bits each) 1,000,000 address records in the index file of the fully indexed example above.
So you'd prefer partially indexed file structures when the data records are small to medium on average in size, and fully indexed file structure for files with large data records. (Assuming that you had varying sized records, and so did not want to used direct access file structure due to wasted memory.)
Sequential searches
O n. This is because the bigger the file, the longer it will take on average to find what you are looking for. And it is a direct correlation; one file twice the size of another file will take on average exactly twice as much time to perform searches.
Direct Access
O 1. The size of the file makes no difference at all. The searches always take exactly the same amount of time, irregardless of the number of records.
Partially Indexed
O n for the search through the index file + O n for the search through the group, so you could summarize it as On (index file) + O n (grouping), remembering that your index file is smaller than the equivalent fully indexed index file. And actually the point is that the bigger the file the more time it would take, in direct proportion, so we would properly just list the Big O as O n.
Fully Indexed
O n for the search through the index file + O 1 for the direct access to the record. But with Big O we usually drop the smallest factor, so it would also be just O n.
So as you can see, the Big O in this case doesn't help us so much, since three of our choices are O n.
Here's a table to summarize good file structure choices:
| Sequential File Structure | Choose when records are of widely varying length, but you won't be searching for individual records from the file; rather you will read the whole file into RAM before working with it. So there's no need to waste space with an index file. |
| Partially Index File Structure | Choose when records are of widely varying length, and you will be searching from the file itself, and the average record is not too big. |
| Fully Indexed File Structure | Choose when records are of widely varying length, and you will be searching from the file itself, and the average record is big. |
| Direct Access File Structure | Choose when the record sizes are fairly uniform, and you will be searching from the file itself. Or regardless of record sizes, you are not worried about memory wastage; you just want fast searching access from the file itself. |
----------------------------
Logical Organization vs Physical Organization
By physical organization we mean how the records are actually physically on the hard drive or other storage media. Are they all together, i.e. contiguous, or are they scattered, i.e. fragmented. So for example, regarding physical organization, direct access files' records is best when the records are contiguous, otherwise the searching by multiplying the record size by the record number being searched for would not so easily work. Though there is more to this story too, but generally, physical organization is physically what's going on at the hardware level.
Logical organization is how the file or other structure in RAM (like arrays) are treated by the program. Are we searching a RAM array sequentially, or are we doing so in a binary search way. In both cases, the data will be in the same physical arrangement, but the way the program is working with the data in both cases is very different logically. Or in the case of files, are we accessing them via sequential searching, partial or fully indexed ways, or directly? In all cases, the data part of the files can be stored physically the same way.
A couple of notes on terminology:
You should note that "sequential" implies ordered, i.e. sorted. So really, a truly sequential file should be sorted. But the way that it actually works it doesn't have to be, since when we are looking for something we look through the whole file until we find it, whether it is sorted or not. Though one advantage of being stored sorted is that it is ready to be searched by a binary search if it is all read into memory. Meantime, if it is not stored sorted/ordered, then we could rather more properly refer to it as a serial file rather than a sequential file.
And one other note on terminology, we generally use "sorted" for RAM stuff like arrays because in RAM they are relatively easily sortable, and we "ordered" for flies, implying a set state.
Ordered vs. Unordered Records
So sequential files can be ordered or un-ordered. Meantime, partially indexed files have to be ordered, and direct access files will be un-ordered by nature.
For partially indexed files structures to work properly, the data part of them needs to be ordered. If we go through the index part and find the address for, for example, the "C"s group, well then that part of the data file needs to have all the Cs there, so the data file needs to be alphabetized; i.e. sorted/ordered. (Meantime the index itself doesn't need to be sorted.)
In terms of direct access, each hash value is unpredictable before it is done, so the records will be placed randomly through the file (though this randomness will be the "same randomness" when re-calculating the has value during finding.) So by the nature of hashing, direct access files have no order such as alphabetization or anything else.
The above section brings up an good, but almost overlooked point. Why would we actually do our searching from a file in the slow hard drive. Why not load the file into fast RAM and search for it there using a binary search for example. The answer is that we would use searching directly from the hard drive in two situations: 1. we are only looking for one or a few records, and we don't need to bother with the time or the RAM resources of loading the whole file., and 2. when the file is too large to fit in RAM.
The Need for External Sorts
And the previous section brings up one other question. If the file is too big to load into RAM, then how would we ever sort it in the first place? The answer is generally: an external sort. And the specific answer quite often, and definitely within the scope of IB CS HL is: The Merge Sort. The merge sort is a way of sorting a large file in storage (or indeed a large array in RAM memory) by splitting it in half again and again and again, and getting down to the smallest groupings, sorting them, and then merging the sorted groups back up. So you are shuffling parts of the file back and forth to RAM, and eventually have the whole file sorted on the hard drive or other storage device.
Finally: What Java File Structure Classes Do I Choose in IB CS, and When?
Well first of all you need to realize that sooner or later with your programs you are going to have to make files. Otherwise you won't be able to save data beyond your session in RAM. So what are your options. Really there are two options for IB CS, and they are both pre-made Java classes which you can use:
Sequential Files: the FileWriter class, and FileReader class.
FileReader works very similarly to BufferedReader, which we've already used for input from the keyboard.
Choose to use this combo of classes when the files you will write and read are smallish or not too big, and also when you will be doing frequent searching and sorting in RAM, and so will have to read the whole file into RAM memory anyway.Direct Access Files: the RandomAccessFile class.
Choose to use this when either your files will be really too big to be shuffling in and out of RAM, or when you will only occasionally be going to them to search for a record or two.
Though you'll want to keep in mind that three out of your 10 Mastery Aspects for your internal assessment can be the full use of the RandomAccessFile.
So you probably won't be working with either partially or fully indexed files in this course.
{kind=link}
{kind=link}