Abstract Data Types Part 2
(notes below)
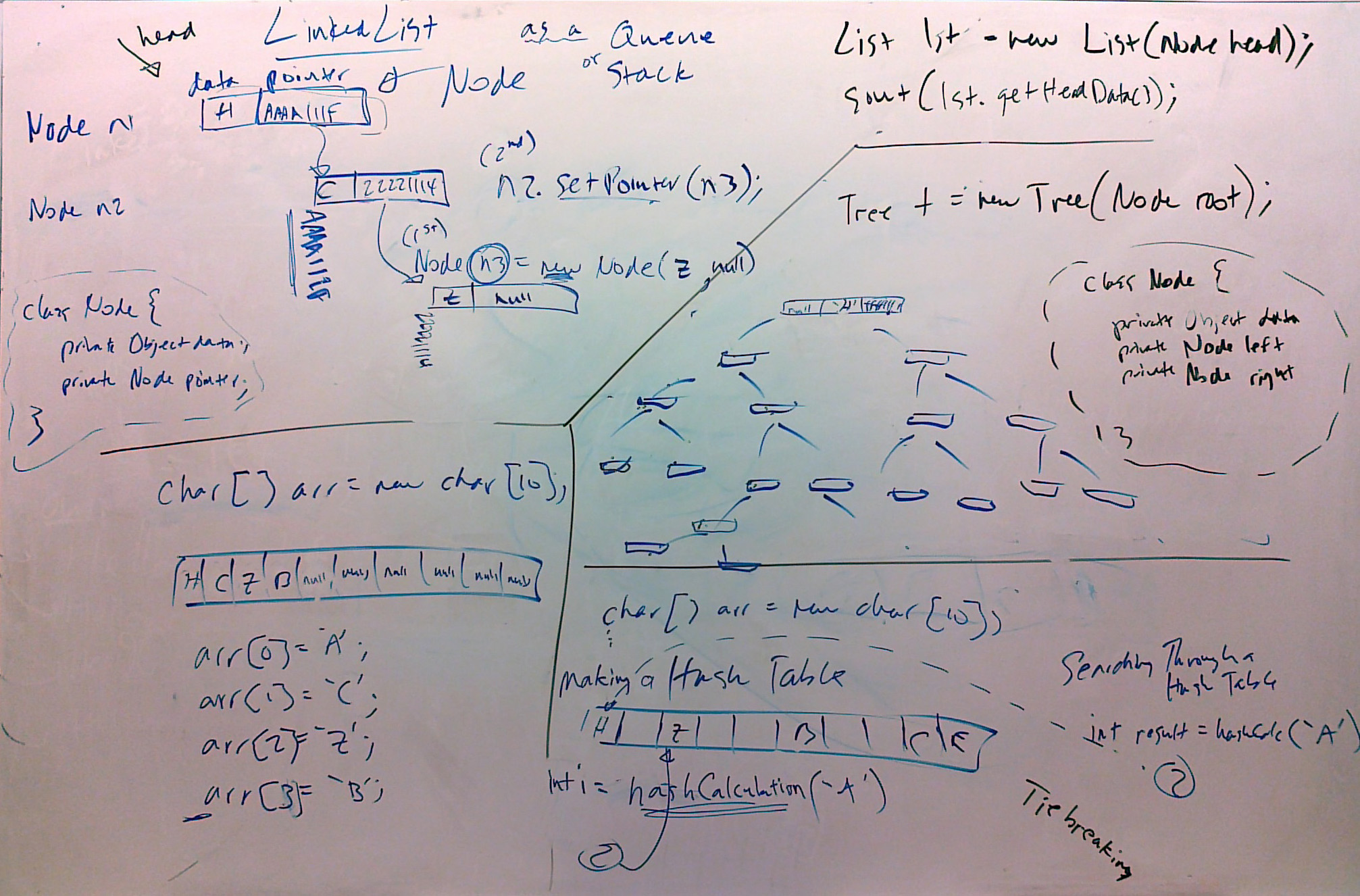
Arrays ( Arrays are not an abstract data type, rather they are a Java data structure. Never-the-less, for comparisons sake, here is some information about them (mainly by way of review)).
Simple Definition: Multiple elements of a particular data type, which can be referred to by one array object variable, and accessed through the element index number.
Physical Memory Level Structure: Contiguous (i.e. touching each other) memory locations; the total memory equalling the size of each element times the number of elements. Elements are most often added sequentially starting with the 0th element, on up to the length-1th element. Very often arrays are sorted so that a binary search can be used.
Logical Organization: Mirrors the physical organization; a series of elements next to each other, either ordered or unordered.
Creation: Created by declaring an array variable which is assigned memory equal to the data type memory requirement times the declared number of elements:
int [] intArray = new int[10]; intArray[0] = 23424; etc.
Access: Accessed using the array variable name in conjunction with the array element operators surrounding the element number to be accessed.
System.out.println(intArray[3]);
Dynamic or Static? Arrays are static with regards to the amount of memory they take up; there is no way to increase or decrease the amount of memory they take up once they are declared. So not great memory efficiency in this regard.
Searchability: If unordered, arrays must be seached sequentially until the key is fond. But if ordered, a binary search (Big O log2 n) can be used to quickly find the key.
Hash Tables ADT
Simple Definition: An array-like data stucture in which elements all reside in one contiguous area of memory, but the location of each element is based on a hash calculation; the same hash calculation can be used to directly access the element, making searching very fast.
Physical Memory Level Structure: Contiguous (i.e. touching each other) memory locations; the total memory equalling the size of each element times the number of elements - the same as arrays. But unlike arrays, the data of an un-full hash table will be scattered throuout the hash table space.
Logical Organization: The position of each element within the hash table is un-important, since a calculation will be used to perform direct access of it. Though, logically (and, in fact, physically as well) in the case of ties, elements whose calculation yields the same result will (most often) be stored serially beside each other.
Creation: As an instance of an ADT created by a programmer, the hash table is constructed according to the methods that he/she makes. But generally, a certain amount of space has to be reserved, and then a calculation is done with some key feature of the data which yeilds an integer with a value between 0 and one less than the length of the hash table.
String [] myStringHashTable = new String[5]; hashValue = ..............//some sort of calculation yeilding an integer between 0 and 4 myStringHashTable[hashValue] = "hello"; etc.
Access: Elements accessed with exactly the same hash calculation as was used to place the elements. (If a calculation on a certain String, for example, came up with the result 2, then when the calculation is repeated during an accessing function, then 2 will also be the result, there-by directly locating what is being looked for at element 2.)
Dynamic or Static? Like the array, a hash table is a static size throughout its lifetime. So it is equally inefficient in terms of memory, particularly if not very full.
Searchability: Theoretically, given all unique hash results, the searching only takes one step - directly to the item to be found. With ties in the calculation of hash results, it is a little less direct, and so a little slower. So the more uniuque the hash calculation results can be made to be, the more efficient the searching is. (Big O 1).
Linked List ADT
Simle Definition: A series of data nodes linked together by pointers, which know the address of the next node in the list; access is usually intended to be from one end of the list only.
Physical Memory Level Structure: Non-contiguous - i.e. scattered throughout RAM.
Logical Organization: The elements (nodes) are treated as a list, all linked together like the links in a chain. But there are two main ways of accessing elements: either from the front or from the rear of the list. Popped off the back, in a Last In First Out (LIFO) fashion sees a list logically treated as a stack. "Enqueued" off the front of a list, in a First In First Out (FIFO) fashion, see the list logically treated as a queue.
Creation: The programmer creates two classes: a Node class, and a List class to link up the nodes. A new Node is created by finding new memory for it, and then pointing the former last link in the list to it, and so on and so on. The node of adding to a list is most often referred to as "pushing" it onto the list.
Access: Access is usually done by "popping" off the "rear" of the "stack" or "enqueueing" off the "front" of the "queue". It is possible to traverse through a list, in order to find something, but this is inefficient; a tree makes for a bitter structure for random searching.
Dynamic or Static? A list is dynamic; it grows and shrinks as nodes are added and removed. This makes it very memory efficient.
Searchability: Poor. Though it is possible to traverse through a linked list, it is usually used in the stack or queue logical way, in which we are not searching; rather we are just accessing the first or last element, whatever it may be. (Big O n).
Binary Search Tree ADT
Simple Definition: A linked data structure in which each node is linked to a "left" and a "right" node; this makes searching able to be done in a binary way on a dynamic data structure.
Physical Memory Level Structure: Non-contiguous - i.e. scattered throughout RAM.
Logical Organization: The elements (nodes) are linked in a tree structure, in which each node branches to one, two, or no other nodes. Links are based on some sort of logical comparison; "lesser" nodes being linked to the left, and "greater" nodes being linked to the right.
Creation: The programmer creates two classes: a Node class, and a Tree class to link up the nodes. Once memory for a new Node has been found, then, starting at the root node, the perfect place to link the node is acheived by traversing through the tree, asking at each node if the new node is "lesser" or "greater" than a particular node.
Access: Access is usually done for a specific element, and so is achieved via searching (see the searchability point below).
Dynamic or Static? A tree is dynamic; it grows and shrinks as nodes are added and removed. This makes it very memory efficient.
Searchability: Excellent, since it is done in a binary way. The same process as was used to create the tree is repeated: starting at the root node, the element being searched for is found by asking at each node along the way whether it is "lesser" or "greater" than it. So (Big O log 2 n).